在大型電商平臺中,一個商品同時歸屬于多個分類是常見的業務場景。例如,一款智能手機可能同時出現在“手機通訊”、“數碼配件”甚至“禮品推薦”等多個分類目錄下。這種一對多的映射關系,在數據量達到億級規模時,對商品詳情頁的架構設計提出了嚴峻挑戰。本文將深入解密支撐億級商品詳情頁的技術服務架構,其核心演進路徑正是圍繞高效、靈活地處理“商品-多分類”這一關系而展開。
第一階段:集中式數據庫與直接關聯
早期架構通常采用集中式關系型數據庫(如MySQL)存儲商品與分類的關聯關系,通過建立“商品-分類”關聯表來實現。當用戶訪問某個分類時,系統通過SQL聯表查詢快速獲取該分類下的商品ID列表,再根據ID查詢商品詳情。這種方案的優點是邏輯簡單、數據強一致。但隨著商品與分類數據量的爆炸式增長,尤其是在促銷期間的高并發訪問下,數據庫的聯表查詢和I/O壓力成為瓶頸,頁面響應延遲明顯增加,難以支撐億級數據的實時高效訪問。
第二階段:引入緩存與讀寫分離
為緩解數據庫壓力,架構演進中引入了多級緩存策略。使用Redis等內存數據庫緩存熱門分類下的商品ID列表以及商品詳情數據。當商品分類信息更新時(如商品上架到新分類),系統會異步更新緩存。數據庫層面實施讀寫分離,將讀請求導向從庫。這一階段顯著提升了讀取性能。它未能根本解決“商品-多分類”帶來的復雜性:一個商品信息的變更(如價格、庫存)需要失效或更新所有關聯分類下的緩存片段,維護一致性成本高昂,緩存命中率在長尾分類下不理想,且系統擴展性依然受限。
第三階段:數據異構化與原子服務
這是架構演進的關鍵轉折點。核心思想是將“商品詳情頁”本身作為一個獨立的數據聚合體進行構建和存儲,而非每次動態拼裝。具體措施包括:
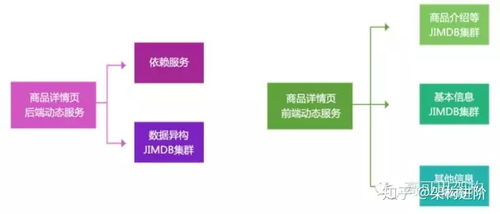
- 數據異構化:構建獨立的“商品詳情”數據存儲(如使用HBase、OceanBase或ES),其每條記錄就是一個完整的、渲染好的商品詳情數據模型。當后臺更新商品基礎信息或分類關系時,通過消息隊列(如Kafka)觸發一個異步的“詳情頁構建引擎”。該引擎會拉取所有相關的商品、分類、營銷數據,并生成一個新的、包含了所有適用分類上下文(如分類名稱、面包屑導航)的詳情頁數據快照,寫入異構存儲。這意味著,一個商品有N個分類,理論上就可能生成N個不同側重點的數據快照(實踐中會進行合并優化)。
- 原子服務拆分:將分類服務、商品基礎服務、庫存服務、價格服務等拆分為獨立的微服務。詳情頁構建引擎通過調用這些原子服務獲取數據。服務之間解耦,獨立伸縮。
- 智能路由與靜態化加速:用戶請求到達時,接入層根據URL中的分類ID,直接路由到異構存儲中對應的、已預先構建好的詳情頁數據,實現近乎靜態頁面的訪問速度。多級緩存(CDN、本地緩存)用于存儲最終渲染的HTML或JSON數據。
第四階段:平臺化與彈性伸縮
在第三階段基礎上,架構進一步演變為一個技術服務平臺,其特征是:
- 實時與最終一致性結合:對于價格、庫存等強實時性數據,采用“異步構建快照+實時服務接口兜底”的方式。即詳情頁展示快照中的庫存,但下單前調用實時庫存服務進行最終校驗。
- 智能化數據處理:利用大數據平臺分析商品與分類的訪問模式,智能預熱緩存,優化詳情頁數據構建的優先級和粒度。
- 彈性伸縮與容災:所有服務無狀態化,可基于容器化技術(如Kubernetes)快速彈性伸縮。存儲層多地域部署,實現異地多活,保障高可用性。
- 統一網關與服務治理:通過API網關統一接入,提供服務發現、流量控制、熔斷降級等治理能力,確保“商品-多分類”這一復雜調用鏈路的穩定性。
技術
從直接依賴關系型數據庫聯表,到通過數據異構化將“商品-多分類”的復雜性在寫入時消化,生成可直接讀取的聚合數據,是億級商品詳情頁架構演進的核心理念。這種架構將計算密集型的數據組裝過程從實時查詢路徑中剝離,以空間(存儲多份聚合數據)和最終一致性換取了極致的讀取性能和系統擴展能力,從而能夠穩健地支撐海量商品、復雜分類關系下的高并發訪問,為業務提供了強大的技術服務底座。